Smntx Architecture
Smntx is composed of a set of REST services. Through these services a diverse range of client applications can access Smntx functionality. The following diagram illustrates the use of Smntx through 1) a web interface, 2) programatically though a high level programming language, 3) using a specialiszed scientific workflow engine. Smntx includes a persistent data model to store information describing users and instances. All NLP results and provanance information is stored and indexed for efficient real-time querying. Smntx is designed to utilize arbitrary NLP engine(s) to process and annotate unstructured clincal text. At present Smntx includes a MetaMap NLP engine wrapper, we are aiming to continue developing wrappers for other leading NLP engines.
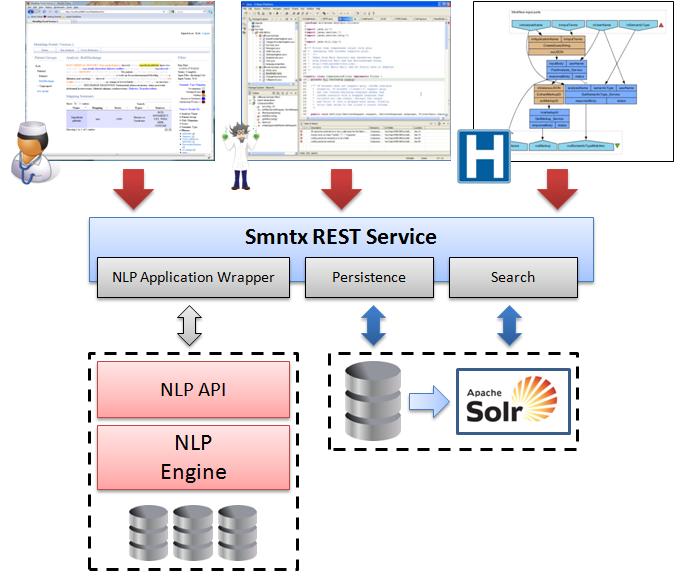
High Level Architecture
The Smntx architecture is composed of multiple separate components: client GUI, Smntx REST API, persistance and indexing backend repositories, and the MetaMap NLP engine.
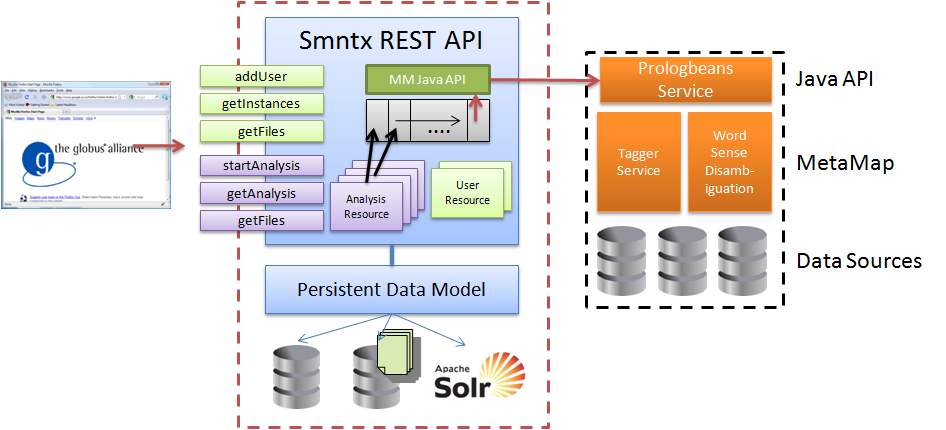
The MetaMap server requires two different prolog-based services (Tagger service and Word Sense Disambiguation service) to operate. A collection of data sources must also be present on the server in order to classify concepts. To access MetaMap programatically Smntx relies on the MetaMap Java API being installed and configured separately from MetaMap. This API uses prologbeans to create a socket interface to the prolog application, a lightweight Java abstraction layer is provided to instantiate a MetaMap instance and retrieve results.
The Smntx REST API is a Jersey based Java web application. It includes 5 main resource types (Users, Groups, Instances, Markup, and Search) and an associated interface to manipulate these resources. A persistent data model maintains user and instance state. To execute an analysis of a given document Smntx includes a FIFO (FCFS) queue of requests. A thread pool is used to asynchronously execute tasks from the queue. For simple queries an interactive (synchronous) text method is available to invoke the NLP engine and return results. This architecture supports distribution of both the MetaMap engine and Smntx.
REST Interface
The REST interface is documented here
NLP Execution
At present Smntx supports only the MetaMap NLP engine (http://metamap.nlm.nih.gov/). MetaMap is a prolog based NLP application used in the medical field to map biomedical text to the UMLS metathesaurus. Given a set of terms MetaMap matches each term against a set of predefined data sources. MetaMap includes a Java-based API that creates a server to expose prolog functionality to consumers, the API includes client side Java libraries to invoke the server application.
Smntx uses a MetaMap client wrapper to execute MetaMap remotely using the Java API. The client wrapper includes three invocation methods: batch mode from string and file, and interactive mode (only from string).
Void invokeFromFile(String file, List<String> serverOptions, String outputFile)
String invokeFromStringInteractive(String terms, List<String> serverOptions)
These three methods all synchronously invoke metamap using the MetaMap API. The two batch modes are queued and executed by a thread. The thread pool is created with a predefined number of threads that wait for a queue events. When free they take the first analysis job off the queue (FIFO) and call the appropriate invocation method through the MetaMap Client wrapper. Each method retrieves the results, stores and indexes results, writes a summary to a file, and annotates the input terms with predefined HTML tags.
Annotated Markup
The MetaMap service includes the option of generating markedup HTML input terms. Markup is created server side using the java based result object. This annotation is performed server side as it is a potentially expensive operation involving scanning the input terms and matching with the results. The result object is iterated through discovering all mappings and candidates for each phrase. The phrase is found in the original input terms and wrapped with HTML markup. The markup includes a call to a static callback JS function that displays the information. All candidate and mapping information is therefore included in the function call. For example the input terms “the patient” is marked up:
Security
Smntx can be configured to use SSL, we have tested Smntx using SSL on Jetty with a simple server side filter and a basic SSL Smntx client. Access to other users's files, analysis results, and information is prohibted through the Smntx service. Physical data is not currently encrypted in the database or on the file system, however we are investigating appropriate encryption schemes. When logging into the systems users are able to use a predefined Smntx password or existing UTS credentials.
Data Model
Smntx uses OpenJPA to define a persistence model based on multiple java beans, this model can therefore be deployed to *any* RDBMS. The core tables are:
USERACCOUNTThe user account table stores information about registered users including their name and isolated storage path. A default patient group is included to map non-grouped NLP analyses. A unique storage directory is created becuase user feedback indicated it is important to keep data private. Smntx isolates individual user paths where all user data is to be stored.
- ID (BIGINT)
- DIRECTORYPATH (VARCHAR)
- NAME (VARCHAR)
- DEFAULTPATIENTGROUP_ID (VARCHAR)
The patient group table stores information about groups created by a user.
- ID (BIGINT)
- PATIENTGROUPNAME (VARCHAR)
- PARENTPATIENTGROUP_ID (VARCHAR)
- USERACCOUNT_ID (VARCHAR)
The instance table maintains information related to a single NLP analysis. Included is provenance information related to the parameters used to execute the analysis, mappings to users and groups, and the results. Instance type defines what type of application it is (in this case it is always metamap). Args is a string which specifies the command line arguments to invoke the application (provenance). Instance Path is the path to files relating to this instance (e.g input/output). InputTerms is the input query, alternatively input file can be specified from which the input terms are loaded. The interactive boolean defines if the instance is running in interactive or batch mode. Result is a string that stores the result of application invocation -- currently it is used to store the filename of the output file. Status stores the current progress of the instance (Configured, Running, Completed, Failed). Markedup ID is a reference to the marked up content if it exists.
- ID (VARCHAR)
- APPLICATIONNAME (VARCHAR)
- ARGS (VARCHAR
- DATE (BIGINT)
- INPUTFILE (VARCHAR)
- INPUTFILEPATH (VARCHAR)
- INPUTTERMS (CLOB)
- INSTANCEPATH (VARCHAR)
- INSTANCETYPE (VARCHAR)
- INTERACTIVE (SMALLINT)
- RESULT (VARCHAR)
- STATUS (VARCHAR)
- PATIENTGROUP_ID (VARCHAR)
- MARKEDUP_ID (VARCHAR)
- USERACCOUNT_ID (BIGINT)
The markup table stores annotated (processed) medical text. This information is used to display coded results in HTML.
- ID (VARCHAR)
- MARKUPOBJECT (CLOB)
- MARKUPTEXT (CLOB)
- INSTANCE_ID (VARCHAR)
The search table stores saved and preprocessed search results for users.
- ID (VARCHAR)
- BIGINT
- NUMRESULTS (INTEGER)
- SEARCHNAME (VARCHAR)
- SEARCHTERMS (VARCHAR)
- USERACCOUNT_ID (VARCHAR)
To abstract the complexities of storing and accessing the data model there is a QueryHelper class (DAO). This object includes methods to store, retrieve and update data stored in the DB. In addition both Objects(UserAccount and Instance) are also JAXB annotated such that they can be serialised into JSON and are therefore used directly in the REST services listed below.